都市デジタルツインの開発において、三次元(3D)建物のモデリングは極めて重要な焦点となっています。都市環境における3D建物再構築のために数多くのアプローチが提案されてきましたが、そのほとんどは特定地域におけるデータ欠損に対応できず、より効率的なアプローチへのさらなる改善を妨げています。人工知能生成コンテンツを用いた新興の手法は、厳格なデータソース要件なしに近似的なデジタルカズン(Digital Cousin)モデルを提供しますが、本研究ではそこから建物デジタルカズン(Building Digital Cousin)を導出し、効率的な実世界の3D都市近似モデリングとして、シミュレートされた建物デジタルカズン表現を作成するための複数の制御因子を組み込んだ生成フレームワークを提案しました。
本フレームワークは、建物フットプリントと建物関連パラメータを生成条件として使用し、ピクセル単位の建物高さマップを生成してから3D構造を再構築することで建物形状を近似します。このアプローチは、既存の大規模画像生成モデルから豊かな事前学習済みの重みを最大限に活用し、満足のいく結果を生み出します。定量的および定性的評価において、本提案フレームワークは優れた性能を達成し、平均二乗平方根誤差(RMSE)は0.27m未満、スケーリング精度は96%以上となり、いくつかのベースライン手法を上回りながら、City3DやSimplyCityなどの既存の最先端再構築手法に匹敵する一方で、必要とする視覚データ参照ははるかに少なくなっています。並びに、PLATEAUデータセットのLoD1白箱モデルとの比較では、幾何学的近似性が50%改善されたことが示され、フレームワークの堅牢性と適応性が確認されました。
Development of urban digital twins critically focuses on modeling three-dimensional (3D) buildings. Although numerous approaches have been proposed for 3D building reconstruction in urban environments, most cannot handle data deficiencies in specific areas, which prevents further improvements into more efficient approaches. While emerging methodologies using artificial intelligence-generated content provide alternative 3D digital cousin models without strict data source requirements, this study derived building digital cousins from it and proposed a generative framework incorporating multiple controlling factors for creating simulated building digital cousin representations as simulated approximations for efficient real-world 3D urban modeling.
Our framework uses building footprints as a graphical control and parameter series as an appearance control to approximate building geometries by generating a pixel-wise building height map and then reconstructing the 3D architecture of the second level of details (LoD). This approach fully utilizes abundant pre-trained resources from existing large visual models and yields satisfactory results. In quantitative and qualitative evaluations, our proposed framework achieves excellent performance, with an average root mean square error (RMSE) lower than 0.27 m and a scaling accuracy higher than 96%, surpassing several baseline methodologies and competing with existing state-of-the-art reconstruction methods such as City3D and SimpliCity, while requiring far fewer visual data references. A comparison with LoD1 ground-truth models of the PLATEAU dataset demonstrates a 50% improvement in geometric proximities, confirming the robustness and adaptability of the framework.

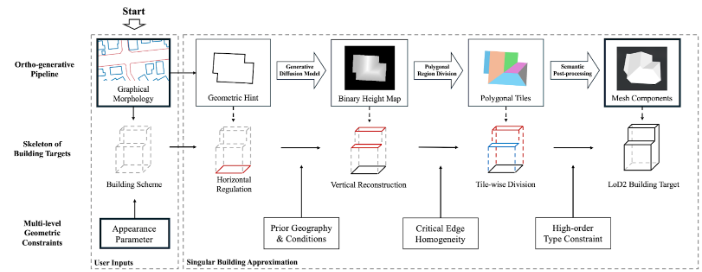
図1:本研究の全体像。建物輪郭線(フットプリント)とパラメータの入力から最終的な三次元建物モデルを構築するパイプラインが示された。
Fig.1: Overall illustration of the proposed variable-controlled generative framework, starting from the left-side user inputs including building graphical shapes and appearance parameter series.
Citation:
Liao, L., Ogawa, Y., Zhao, C., & Sekimoto, Y. (2025). ControlBldg: A variable-controlled generative framework for conditioned modeling of vast 3D urban buildings. ISPRS Journal of Photogrammetry and Remote Sensing, 230, 581–598. https://doi.org/10.1016/j.isprsjprs.2025.09.026